
At runtime, the Job SCORE can be examined to identify:
1. Number
of UNIX processes generated for a given job and $APT_CONFIG_FILE
2. Operator
combination
3. Partitioning
methods between operators
4. Framework-inserted
components - Including Sorts, Partitioners, and Buffer operators
Set $APT_DUMP_SCORE=1 to output the Score
to the DataStage job log
For each job run, 2 separate Score Dumps are written
to the log
- First score
is actually from the license operator
- Second score
entry is the actual job score
Job scores are divided into two sections
1. Datasets
- partitioning and collecting
2. Operators
- node/operator mapping
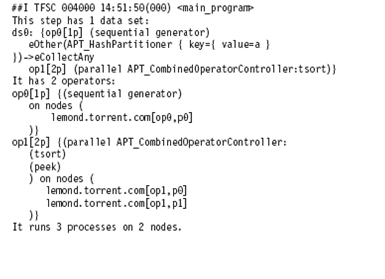
Example score dump
The
following score dump shows a flow with a single data set, which has a hash
partitioner, partitioning on key ″a″. It shows three operators: generator,
tsort, and peek. Tsort and peek are ″combined″, indicating that they have been
optimized into the same process. All the operators in this flow are running on
one node.
The DataStage Parallel Framework implements a producer-consumer
data flow model
Upstream stages (operators or persistent data sets)
produce rows that are consumed by downstream stages (operators or data sets)
Partitioning method is associated with producer. Collector
method is associated with consumer. “eCollectAny” is specified for parallel
consumers, although no collection occurs!
The producer and consumer are separated by the
following indicators:
-> Sequential to Sequential
<> Sequential to Parallel
=> Parallel to Parallel (SAME)
#> Parallel to Parallel (not SAME)
>> Parallel to Sequential
> No producer or no consumer
May also
include [pp] notation when Preserve Partitioning flag is set
At runtime, the DataStage Parallel
Framework can only combine stages (operators) that:
1. Use the
same partitioning method
Repartitioning
prevents operator combination between the corresponding producer and consumer
stages
Implicit repartitioning (eg.
Sequential operators, node maps) also prevents combination
2. Are
Combinable
Set
automatically within the stage/operator definition
Set within DataStage Designer: Advanced stage
properties
The Lookup stage is a composite operator. Internally it contains more than one component,
but to the user it appears to be one stage
1. LUTCreateImpl
- Reads the reference data into memory
2. LUTProcessImpl
- Performs actual lookup processing once reference data has been loaded
At runtime, each internal component is assigned to operators
independently